BlogIndustry Insights
AI Bubble or adoption cycle? A Founder’s Guide

Konstantin BuzzResearch Lead
5 min read

A cautious realist’s view: where speculation ends and repeatable ROI begins – and how to judge your readiness for hybrid intelligence.
There’s a real frenzy around AI right now. Everyone’s trying to catch the wave, and yes – there is a bubble. The gold-rush mentality invites abuse and shortcuts. The question is not whether froth exists, but what survives after it pops: is this another dot-com bubble? Or is it a modern tulip mania, one that could further shake the economy and business culture – if not public norms.
A fresh cautionary tale: Deloitte agreed to partially refund Australia’s government after a AU$440,000 report was found to contain fabricated citations and other errors. The firm later acknowledged GenAI tools (Azure OpenAI / GPT-4o) were used in the drafting. A nice reminder that without proper validation and human-in-the-loop controls, “smart” tools become brand risks.
Greenwashing has given way to AI washing – overstated or misleading claims about AI use. Regulators are trying to circle it: The U.S. SEC has already brought cases for false AI claims and marketing violations.
In parallel, enterprise spend keeps compounding: IDC expects global AI spending to reach roughly $632B by 2028. That’s not hype posts – that’s budget lines.
The scale is hard to ignore. In recent months, reports have valued OpenAI at nearly half a trillion dollars, with reports also pointing to trillion-scale partnerships with cloud and chip companies. These include 10-gigawatt data center plans, multi-year cloud commitments, and a rumored "Stargate" program that sounds more like an energy project than an IT upgrade. Set that against today’s revenue (orders of magnitude smaller) and you get the dissonance that makes people shout “bubble.”
And yet it’s not only air. A leading cohort of AI-first companies is already booking meaningful ARR. OpenAI’s mid-2025 revenue is real (billions, not millions). Younger startups are hitting early revenue thresholds faster than classic SaaS did. Under the hood, capability-to-price curves keep bending: the same budget buys more output every few months, even if latency and long-context surcharges complicate the picture. That’s why serious buyers keep spending; the unit economics improve as you instrument the work. Yet, expectations and capex clearly run ahead of the current P&L.
Both tribes admit overheating. Builders and investors use the word “bubble” without flinching. MarketWatch estimates it at ‘17 times the size of the dot-com bubble’. Others argue that many industrial bubbles left useful infrastructure behind. Regulators add a sober note – warning that enthusiasm can outpace fundamentals and snap back fast.
And yet – where will lasting value be found?
Lasting value doesn’t come from demos. A simple rule holds up after every hype cycle: if a workflow leaves evidence, saves measurable time, and can be replayed, it survives. If it can’t be measured or audited, it was marketing. Three patterns look set to endure.
Agentic workflows.
The agents will do the legwork – gather, transform, propose – and then stop for a human decision where risk lives. Crucially, they leave a trail you can re-run: inputs, steps, outputs, and approvals. And when agents are wired into the systems that move a company – tasks, ticketing, comms, CRMs – their output becomes a state change, not another chat. Those are the agents markets keep paying for.
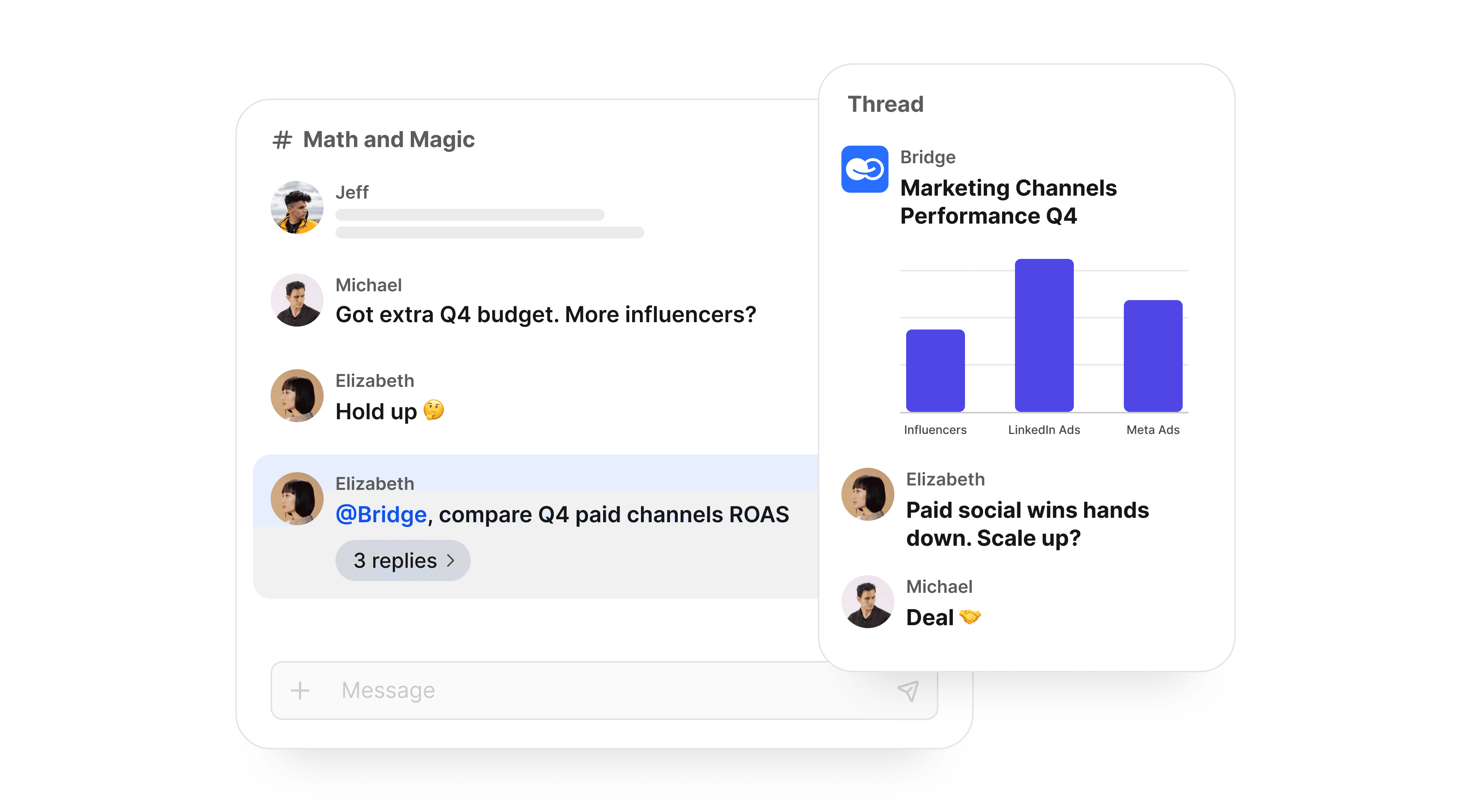
RAG on private data.
The models that endure will show their work. Retrieval-augmented generation (RAG) lets a system answer from approved sources and cite them. In practice, that means a clean, owned library of documents, clear access rules, and routine refreshes so the material stays current. Pair that with regular accuracy checks and simple guardrails – an explanation of where an answer came from and what the model can’t do – and you get something investors and regulators both like: answers that are checkable and repeatable.
Orchestration and telemetry.
Winners will look less like chatbots and more like services you can run. That means end-to-end traces, cost and latency per answer, versioned prompts and policies, and someone clearly on the hook when things break – backed by dashboards, alerts, and postmortems. Add smart routing and caching so easy questions use cheaper models and common answers aren’t recomputed. When the bills roll in, only the instrumented systems make the cut.
Interfaces will matter – but not the way pitch decks promise. Voice is useful today for capture and hands-free work, but it’s still slower and messier than structured input – an option, not a backbone.
A three-year outlook
2025–2026: hype deflates.
The wrapper era loses steam. Look-alike apps that call a frontier model plus a couple of tools fade as buyers ask whether outputs change state in core systems. Thin wrappers give way to products with orchestration, data stewardship, and evidence trails.
The API/AgentKit rush continues – more products will expose simple ways for agents to act ((API – a product’s doorway; agent kit – starter tools for agents to use it; when capitalized — OpenAI’s brand)). But the beneficiaries shift: by 2026, winners look less like chats and more like services with a spine. Self-checking becomes standard: recursive prompts and multi-agent patterns spread, with models critiquing their own outputs or cross-checking via tools – raising reliability without slowing humans to a crawl.
Inference keeps getting cheaper on average – but unevenly across tasks; long-context and real-time remain pricey. Two practical shifts bite:
— The edge lights up: a surge of IoT and light robotics use cases (inspection, pick-and-pack, facilities) running simple closed-loop routines.
— Protocol gravity: teams tire of bespoke glue; interaction standards emerge for how models call tools, pass state, and hand off to humans.
A few brand names stumble; the tourists leave. Survivors run instrumented pipelines with measurable payback. AI agent delivery pods emerge in narrow scopes – standing up end-to-end workflows (data prep → draft → review → file) under human oversight – useful where rules are strict and variance is low. Investors rotate toward efficiency compounding – optimizers, schedulers, quantization/distillation, and memory compression that yield small but reliable cost/latency gains.
2026–2027: the slow S-curve.
Stacks settle; the story turns from demos to boring utility – much like DevOps + cloud in the 2010s, when experimentation gave way to pipelines, SLAs, and cost dashboards. Companies build internal libraries of tools/knowledge; procurement asks for eval scorecards, provenance, and vendor-neutral plans. Protocol consolidation accelerates: common ways to describe tasks, credentials, and safety rules let agents plug into CRMs, ERPs, and plant systems without bespoke work. Capital favors teams that move metrics at the margin (time-to-decision, $/answer, success@K (share of correct results in the top-K)) and prove they can scale.
By 2028: the infrastructure shift.
Market structure bifurcates:
— Top-tier concentration: a handful of first-rank AI companies assemble super-conglomerates around compute, data, and (in some cases) quantum—owning the heaviest capex layers.
— Viable midsize/SMB winners: AI-first specialists with disciplined, error-free implementations in concrete workflows—where evidence, repeatability, and unit economics are obvious. Buyers prefer systems that show auditability at a glance; in sensitive sectors, sovereign/on-prem footprints become routine checkboxes.
AI recedes into the platform – an option like storage or queues, not a project. Budgets flow to operations and control: SLAs, telemetry, incident response, policy enforcement.
Key risks – what could knock a company out of the market
1) Trust failures (the fast killers).
Overtrusting models, under-verifying outputs, and AI washing erode credibility fast. One public error or misleading claim can shut doors with customers and regulators. Mitigate: human checkpoints on risky actions, evidence/citations by default, plain-language disclosures.
2) Data exposure and security.
Context leaks via logs, caches, or prompt injection; sloppy API joins; unclear retention. A single breach can be existential. Mitigate: least-privilege access, context isolation, red-teaming, secret hygiene, clear retention policies.
3) Unit-economics collapse.
Invisible costs for observability, evals, and rework balloon; long-context and real-time use cases blow up spend; latency misses SLAs. Mitigate: cost/latency per answer on dashboards, model routing and caching, bounded contexts, kill-switches for runaway jobs.
4) Provider lock-in and fragility.
Over-reliance on one model/vendor leaves you exposed to outages, policy shifts, or price changes. Mitigate: multi-model abstraction, exportable prompts/evals, contract exit ramps.
5) Compliance and liability.
Sector rules (PII (personally identifiable information), intellectual property, auditability) plus regulator attention to misleading claims. Mitigate: mapped data flows, audit trails, documented evals, counsel sign-off on marketing language.
6) Structural bottlenecks.
Power, chips, and clean data supply can cap growth or strand capex as tech generations turn over. Mitigate: phased capacity plans, data stewardship, and conservative ROI gates on big builds.
Toward hybrid intelligence
It’s happening, with or without our permission. Machines will take on far more work – orders of magnitude more – than they already have. That doesn’t mean a man vs. machine showdown in any realistic mid-term horizon. It means our decisions, projects, and services will increasingly be produced by hybrids: people, models, and data systems working as one fabric.
Think of hybrid intelligence as a cloud of shared cognition. Algorithms contribute speed and recall; humans add judgment, values, and context; corporate systems provide the records; governments set the rules – fashionably late. Organizations that stay plugged into this fabric – where hybrid intelligence can read the right sources, act in the right systems, and show its work – will simply move faster and make fewer avoidable mistakes. We also expect agentic AI systems to run the full scientific/R&D loop – from proposing hypotheses and designing experiments to running analyses and drafting submissions – while a human principal investigator points them at the right questions.
Hybrid intelligence is a division of labor. Those who remain unplugged will feel slow – a mule on a highway: longer time-to-decision, weaker customer journeys, brittle operations. The shape that endures after the bubble is simple: let models do what they’re good at, keep humans where judgment matters, and wire the two through systems that preserve evidence.
In the foreseeable future, interfaces will thicken the weave. Wearables and ambient audio will turn meetings and fieldwork into usable context; lightweight prompts will sit inside the tools where work already happens. On the horizon, neural interfaces could open a high-bandwidth link between AI systems and human intent.

The last mile: how to prepare – and what “hybrid” already looks like
Work together, early.
Start by building mixed teams – humans and agents in the same loop. Ask AI to research – then to cross-check itself and the team. Teach people to collaborate with AI, learn from it, and teach it back (pair-ops, playbooks).
Stay alert to models, rules, and prices.
Track major model updates and regulatory moves (local privacy and sector rules). Keep an eye on pricing so you don’t overspend on tokens and context. Simple habit: a monthly one-pager with “what changed,” cost deltas, and impact on your workflows.
Practice data hygiene.
Inventory and approve your sources. Decide which are ‘gold’, who maintains them, and how often they refresh. Strip or mask PII (personally identifiable information). Set retention rules. Control caches and temp layers so sensitive context doesn’t leak into logs.
Insert human-in-the-loop at decision gates.
Define the checkpoints, roles, and escalation protocols for high-risk steps. Make approvals part of the artifact (who signed off, when, on what evidence).
Audit access and add telemetry.
If you can’t see it, you can’t scale it. Know the flow of work. Discover who can read/write which sources, what’s being logged, and who approved. Put end-to-end traces in place. Track model versions, token consumption, and latency per answer.
Choose your footprint: cloud or sovereign.
Where policy or client contracts require, plan for on-premises deployments. Otherwise, be explicit about why cloud is acceptable and how you’ll exit if needed.
Try hybrid collaboration
The shift is already visible in tools that live next to the work, not outside it. A typical pattern:
- Agentic flows pull from approved knowledge, draft a plan, and stop at HITL gates for judgment.
- RAG on private data grounds answers in citations from your docs, tickets, and logs.
- Orchestration and telemetry trace every step, with cost/latency per answer on a dashboard and versioned prompts/policies for audit.
- System integration means output isn’t a transcript – it’s a ticket filed, a record updated, a workflow advanced.
These principles already shape a new class of collaborative platforms.
BridgeApp is one built on them. Agents there don’t chat for sport: AI handles routine tasks, decisions happen faster, handovers are fewer, and the logic is observable. You can show the results to auditors, clients, and your own team.
See how BridgeApp can drive real state changes in your business.


